Nota do editor: Usamos varreduras contribuídas por jogadores de locais públicos do mundo real para ajudar a construir nosso Grande Modelo Geoespacial. Esse recurso de digitalização é totalmente opcional – as pessoas precisam visitar um local específico acessível ao público e clicar para digitalizar. Isso permite que a Niantic ofereça novos tipos de experiências de RA para as pessoas desfrutarem. Simplesmente andar por aí jogando nossos jogos não treina um modelo de IA.
Na Niantic, somos pioneiros no conceito de um Grande Modelo Geoespacial que usará aprendizado de máquina em larga escala para entender uma cena e conectá-la a milhões de outras cenas em todo o mundo.
Quando você olha para um tipo familiar de estrutura – seja uma igreja, uma estátua ou uma praça da cidade – é bastante fácil imaginar como ela pode parecer de outros ângulos, mesmo que você não a tenha visto de todos os lados. Como humanos, temos “compreensão espacial”, o que significa que podemos preencher esses detalhes com base em inúmeras cenas semelhantes que encontramos antes. Mas para as máquinas, essa tarefa é extraordinariamente difícil. Mesmo os modelos de IA mais avançados hoje lutam para visualizar e inferir partes ausentes de uma cena ou imaginar um lugar de um novo ângulo. Isso está prestes a mudar: a inteligência espacial é a próxima fronteira dos modelos de IA.

Como parte do Sistema de Posicionamento Visual (VPS) da Niantic, treinamos mais de 50 milhões de redes neurais, com mais de 150 trilhões de parâmetros, permitindo a operação em mais de um milhão de locais. Em nossa visão de um Grande Modelo Geoespacial (LGM), cada uma dessas redes locais contribuiria para um grande modelo global, implementando uma compreensão compartilhada de localizações geográficas e compreendendo lugares ainda a serem totalmente digitalizados.
O LGM permitirá que os computadores não apenas percebam e compreendam os espaços físicos, mas também interajam com eles de novas maneiras, formando um componente crítico dos óculos AR e campos além, incluindo robótica, criação de conteúdo e sistemas autônomos. À medida que passamos dos telefones para a tecnologia vestível ligada ao mundo real, a inteligência espacial se tornará o futuro sistema operacional do mundo.
O que é um grande modelo geoespacial?
Os Large Language Models (LLMs) estão tendo um impacto inegável em nossas vidas cotidianas e em vários setores. Treinados em coleções de texto em escala de internet, os LLMs podem entender e gerar linguagem escrita de uma forma que desafia nossa compreensão de “inteligência”.
Grandes modelos geoespaciais ajudarão os computadores a perceber, compreender e navegar no mundo físico de uma maneira que parecerá igualmente avançada. Análogos aos LLMs, os modelos geoespaciais são construídos usando grandes quantidades de dados brutos: bilhões de imagens do mundo, todas ancoradas em locais precisos no globo, são destiladas em um grande modelo que permite uma compreensão baseada em localização do espaço, estruturas e interações físicas.
A mudança de modelos baseados em texto para aqueles baseados em dados 3D reflete a trajetória mais ampla do crescimento da IA nos últimos anos: desde a compreensão e geração de linguagem até a interpretação e criação de imagens estáticas e em movimento (modelos de visão 2D) e, com o aumento dos esforços de pesquisa atuais, para modelar a aparência 3D de objetos (modelos de visão 3D)
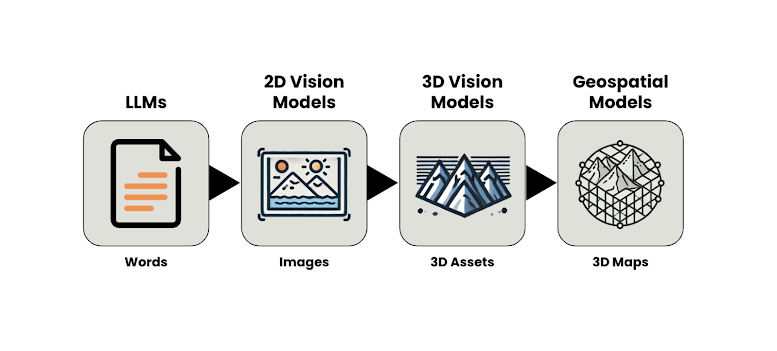
Os modelos geoespaciais estão um passo além dos modelos de visão 3D, pois capturam entidades 3D que estão enraizadas em localizações geográficas específicas e têm uma qualidade métrica. Ao contrário dos modelos generativos 3D típicos, que produzem ativos não dimensionados, um Grande Modelo Geoespacial é vinculado ao espaço métrico, garantindo estimativas precisas em unidades métricas de escala. Essas entidades, portanto, representam mapas de próxima geração, em vez de ativos 3D arbitrários. Enquanto um modelo de visão 3D pode ser capaz de criar e entender uma cena 3D, um modelo geoespacial entende como essa cena se relaciona com milhões de outras cenas, geograficamente, em todo o mundo. Um modelo geoespacial implementa uma forma de inteligência geoespacial, onde o modelo aprende com suas observações anteriores e é capaz de transferir conhecimento para novos locais, mesmo que sejam observados apenas parcialmente.
Embora os óculos AR com gráficos 3D ainda estejam a vários anos de distância do mercado de massa, há oportunidades para que os modelos geoespaciais sejam integrados com óculos de exibição somente de áudio ou 2D. Esses modelos podem guiar os usuários pelo mundo, responder a perguntas, fornecer recomendações personalizadas, ajudar na navegação e aprimorar as interações do mundo real. Grandes modelos de linguagem podem ser integrados para que a compreensão e o espaço se unam, dando às pessoas a oportunidade de serem mais informadas e engajadas com seus arredores e bairros. A inteligência geoespacial, emergindo de um grande modelo geoespacial, também pode permitir a geração, conclusão ou manipulação de representações 3D do mundo para ajudar a construir a próxima geração de experiências de RA. Além dos jogos, os Grandes Modelos Geoespaciais terão aplicações amplas, desde planejamento e design espacial, logística, envolvimento do público e colaboração remota.
Nosso trabalho até agora
Nos últimos cinco anos, a Niantic se concentrou na construção de nosso Sistema de Posicionamento Visual (VPS), que usa uma única imagem de um telefone para determinar sua posição e orientação usando um mapa 3D construído a partir de pessoas que digitalizam locais interessantes em nossos jogos e no Scaniverse.
Com o VPS, os usuários podem se posicionar no mundo com precisão em nível de centímetro. Isso significa que eles podem ver o conteúdo digital colocado no ambiente físico de forma precisa e realista. Esse conteúdo é persistente, pois permanece em um local depois que você sai e pode ser compartilhado com outras pessoas. Por exemplo, recentemente começamos a lançar um recurso experimental no Pokémon GO, chamado Pokémon Playgrounds, onde o usuário pode colocar Pokémon em um local específico e eles permanecerão lá para que outras pessoas vejam e interajam.
O VPS da Niantic é construído a partir de varreduras de usuários, tomadas de diferentes perspectivas e em vários momentos do dia, em muitos momentos ao longo dos anos, e com informações de posicionamento anexadas, criando uma compreensão altamente detalhada do mundo. Esses dados são únicos porque são retirados de uma perspectiva de pedestre e incluem locais inacessíveis aos carros.
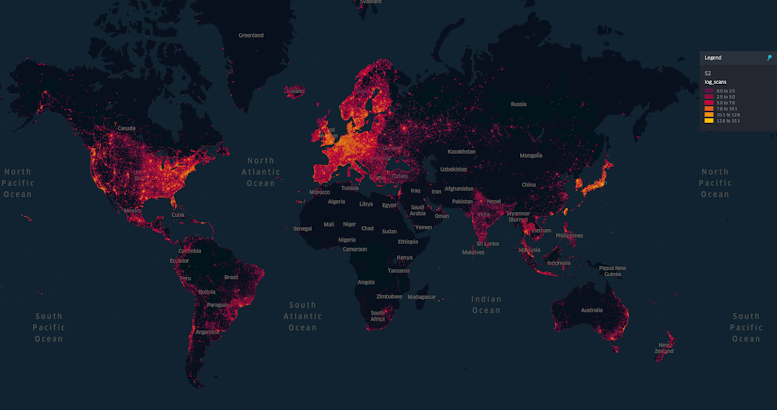
Hoje temos 10 milhões de locais digitalizados em todo o mundo, e mais de 1 milhão deles estão ativados e disponíveis para uso com nosso serviço VPS. Recebemos cerca de 1 milhão de novas digitalizações por semana, cada uma contendo centenas de imagens discretas.
Como parte do VPS, construímos mapas de visão 3D clássicos usando estrutura de técnicas de movimento – mas também um novo tipo de mapa neural para cada lugar. Esses modelos neurais, baseados em nossos trabalhos de pesquisa ACE (2023) e ACE Zero (2024), não representam mais locais usando estruturas de dados 3D clássicas, mas os codificam implicitamente nos parâmetros que podem ser aprendidos de uma rede neural. Essas redes podem compactar rapidamente milhares de imagens de mapeamento em uma representação neural enxuta. Dada uma nova imagem de consulta, eles oferecem um posicionamento preciso para esse local com precisão em nível de centímetro.
A Niantic treinou mais de 50 milhões de redes neurais até o momento, onde várias redes podem contribuir para um único local. Todas essas redes combinadas compreendem mais de 150 trilhões de parâmetros otimizados usando aprendizado de máquina.
Dos sistemas locais ao entendimento compartilhado
Nosso mapa neural atual é um modelo geoespacial viável, ativo e utilizável agora como parte do VPS da Niantic. Também é certamente “grande”. No entanto, nossa visão de um “Grande Modelo Geoespacial” vai além do atual sistema de mapas locais independentes.
Um modelo totalmente local pode não ter cobertura completa de suas respectivas localizações. Não importa quantos dados tenhamos disponíveis em escala global, localmente, eles geralmente serão escassos. O principal modo de falha de um modelo local é sua incapacidade de extrapolar além do que já viu e de onde o modelo o viu. Portanto, os modelos locais só podem posicionar visualizações de câmera semelhantes às exibições com as quais já foram treinados.
Imagine-se atrás de uma igreja. Vamos supor que o modelo local mais próximo tenha visto apenas a entrada da frente dessa igreja e, portanto, não será capaz de dizer onde você está. O modelo nunca viu a parte de trás daquele prédio. Mas em escala global, vimos muitas igrejas, milhares delas, todas capturadas por seus respectivos modelos locais em outros lugares do mundo. Nenhuma igreja é igual, mas muitas compartilham características comuns. Um LGM é uma forma de acessar esse conhecimento distribuído.
Um LGM destila informações comuns em um modelo global em larga escala que permite a comunicação e o compartilhamento de dados entre modelos locais. Um LGM seria capaz de internalizar o conceito de igreja e, além disso, como esses edifícios são comumente estruturados. Mesmo que, para um local específico, tenhamos mapeado apenas a entrada de uma igreja, um LGM seria capaz de fazer um palpite inteligente sobre como é a parte de trás do edifício, com base em milhares de igrejas que já viu antes. Portanto, o LGM permite uma robustez sem precedentes no posicionamento, mesmo de pontos de vista e ângulos que o VPS nunca viu.
O modelo global implementa uma compreensão centralizada do mundo, inteiramente derivada de dados geoespaciais e visuais. O LGM extrapola localmente interpolando globalmente.
Compreensão semelhante à humana
O processo descrito acima é semelhante à forma como os humanos percebem e imaginam o mundo. Como humanos, reconhecemos naturalmente algo que já vimos antes, mesmo de um ângulo diferente. Por exemplo, é preciso relativamente pouco esforço para voltar pelas ruas sinuosas de uma cidade velha europeia. Identificamos todas as junções certas, embora as tenhamos visto apenas uma vez e na direção oposta. Isso requer um nível de compreensão do mundo físico e dos espaços culturais que é natural para nós, mas extremamente difícil de alcançar com a tecnologia clássica de visão de máquina. Requer conhecimento de algumas leis básicas da natureza: o mundo é composto de objetos que consistem em matéria sólida e, portanto, têm uma frente e um verso. A aparência muda com base na hora do dia e na estação. Também requer uma quantidade considerável de conhecimento cultural: a forma de muitos objetos feitos pelo homem segue regras específicas de simetria ou outros tipos genéricos de layouts – muitas vezes dependendo da região geográfica.
Embora as primeiras pesquisas de visão computacional tenham tentado decifrar algumas dessas regras para codificá-las em sistemas feitos à mão, agora é consenso que um grau tão alto de compreensão como o que aspiramos só pode ser alcançado de forma realista por meio de aprendizado de máquina em larga escala. É isso que buscamos com nosso LGM. Vimos um primeiro vislumbre de impressionantes recursos de posicionamento de câmera emergindo de nossos dados em nosso recente artigo de pesquisa MicKey (2024). O MicKey é uma rede neural capaz de posicionar duas visualizações de câmera uma em relação à outra, mesmo sob mudanças drásticas de ponto de vista.
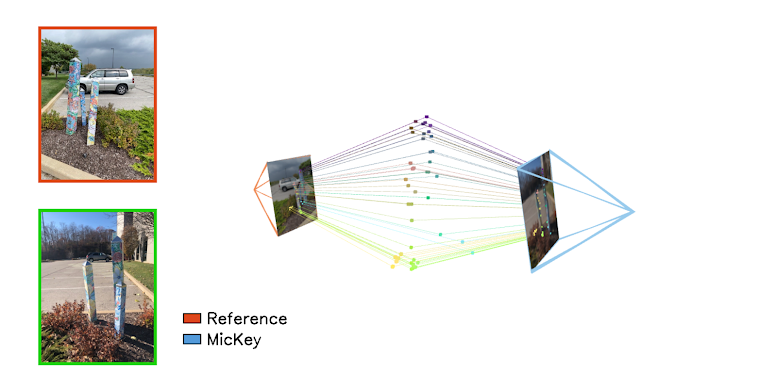
MicKey pode lidar com tiros opostos que exigiriam algum esforço humano para descobrir. O MicKey foi treinado em uma pequena fração de nossos dados – dados que divulgamos para a comunidade acadêmica para incentivar esse tipo de pesquisa. O MicKey é limitado a entradas de duas visualizações e foi treinado em dados comparativamente pequenos, mas ainda representa uma prova de conceito sobre o potencial de um LGM. Evidentemente, para realizar a inteligência geoespacial conforme descrito neste texto, é necessário um imenso influxo de dados geoespaciais – um tipo de dados aos quais muitas organizações não têm acesso. Portanto, a Niantic está em uma posição única para liderar o caminho para tornar um Grande Modelo Geoespacial uma realidade, apoiado por mais de um milhão de varreduras contribuídas por usuários de lugares do mundo real que recebemos por semana.
Rumo a modelos de fundação complementares
Um LGM será útil para mais do que mero posicionamento. Para resolver bem o posicionamento, o LGM precisa codificar informações geométricas, de aparência e culturais ricas em recursos de nível de cena. Esses recursos permitirão novas formas de representação, manipulação e criação de cenas. Grandes modelos versáteis de IA, como o LGM, que são úteis para uma infinidade de aplicativos downstream, são comumente chamados de “modelos de base”.
Diferentes tipos de modelos de fundação se complementam. Os LLMs interagirão com modelos multimodais, que, por sua vez, se comunicarão com os LGMs. Esses sistemas, trabalhando juntos, darão sentido ao mundo de maneiras que nenhum modelo pode alcançar sozinho. Essa interconexão é o futuro da computação espacial – sistemas inteligentes que percebem, entendem e agem sobre o mundo físico.
À medida que avançamos em direção a modelos mais escaláveis, o objetivo da Niantic continua sendo liderar o desenvolvimento de um grande modelo geoespacial que opere onde quer que possamos oferecer experiências novas, divertidas e enriquecedoras aos nossos usuários. E, como observado, além dos jogos, os Grandes Modelos Geoespaciais terão aplicações generalizadas, incluindo planejamento e design espacial, logística, envolvimento do público e colaboração remota.
O caminho de LLMs para LGMs é mais um passo na evolução da IA. À medida que dispositivos vestíveis, como óculos AR, se tornam mais prevalentes, o futuro sistema operacional do mundo dependerá da combinação de realidades físicas e digitais para criar um sistema de computação espacial que colocará as pessoas no centro.
Eric Brachmann e Victor Adrian Prisacariu
